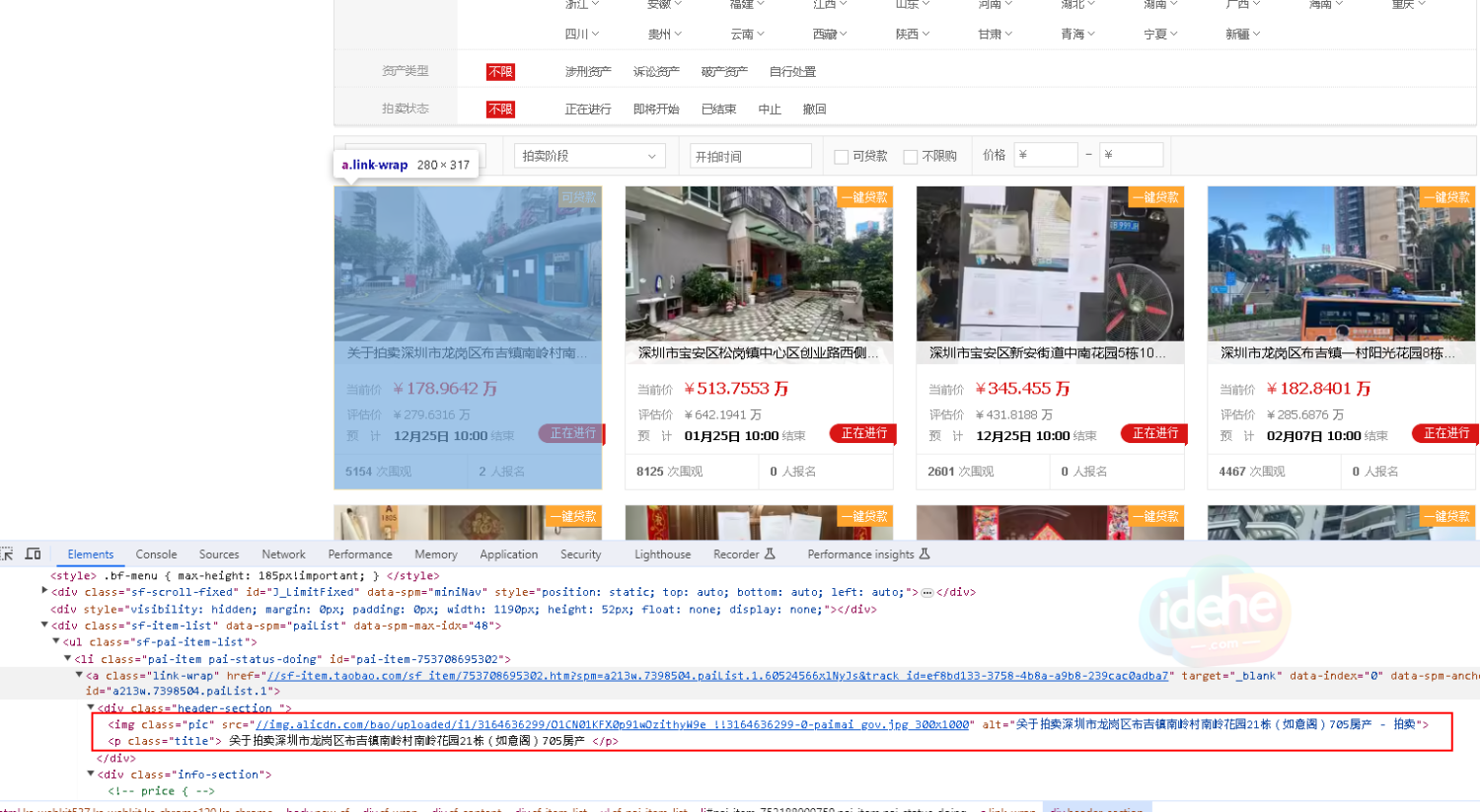
[爬虫1] 爬取阿里某宝的司法拍卖数据
升级到了 selenium 4.16 版本, 不需要 chromedriver.exe文件了 以下开头采用 chrome remote dev tools 方法, 多个chrome 远程调用他, 并且执行. 打开chrome并打开URL2也就是某宝司法拍卖的地址了 其中 url 起始页 实际可以使用 https://sf.taobao.com/list/0____%B9%E3%B6%AB.htm 对应的是广东区 定位到每一个法拍的数据, 可以发现, 缩略图的地址应该是: 但是实际抓取 attribute href 获得是 g.alicdn.com/s.gif 检查, 对 img 这个标签抓取 outterHTML 的 atriibute 得到 所以实际的缩略图url的attribute 应该是 data-ks-lazyload. 实际测试 有可能是 src, 也有可能是 data-ks-lazyload. 其他问题 – 目前还没办法找到 a tag 里面 正确的 href 实际的 […]
Read More[Code] 修个BUG
现在做了一个抓取低风险收益的网站,在这里:http://42.120.16.247/ 抓取的时候发现分级基金A的功能不工作了,仔细打开数据发现是网站栏目的“理论 下折收益”的里面的内容多了一个“-”,不能转换为float形式而出错。找到问题了坚决就简单!if 判断一下值然后改成赋值为-999,哈哈,其他else保持原样,就可以了! Python爬虫内容,好玩好用的!
Read More[Scrawler] 解决雪球爬虫返回403
正常情况下使用urllib2.urlopen 会返回urllib2.HTTPError: HTTP Error 400: Bad Request 错误,需要的cookie 行信息,如果手动填写的话会有过期的问题。 现在终于找到解决办法,用cooklib里面的cookiejar先获取cookie 然后用urlopen就好啦。具体程序看我的python练习档内的jisi2/cookie_get.py文件:https://github.com/hechao/python *** 更新一下,雪球网站的链接http://xueqiu.com/v4/stock/quote.json?code=SH000001%2CSZ399001%2CHKHSI%2CDJI30 是无法直接打开获得cookie的,依然返回400错误。 解决方法就是,所以程序里面先用opener.open打开一下雪球主页,再opener.open这个链接就可以了,应该是传递了cookie的原因, yeah. 改造成一个def了 [python] #! /usr/bin/python #-*- encoding: utf-8 -*- import cookielib, urllib2 def content(index_url): cj = cookielib.CookieJar() opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) # default User-Agent (‘Python-urllib/2.6’) will *not* work opener.addheaders = [ (‘User-Agent’, ‘Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 […]
Read More